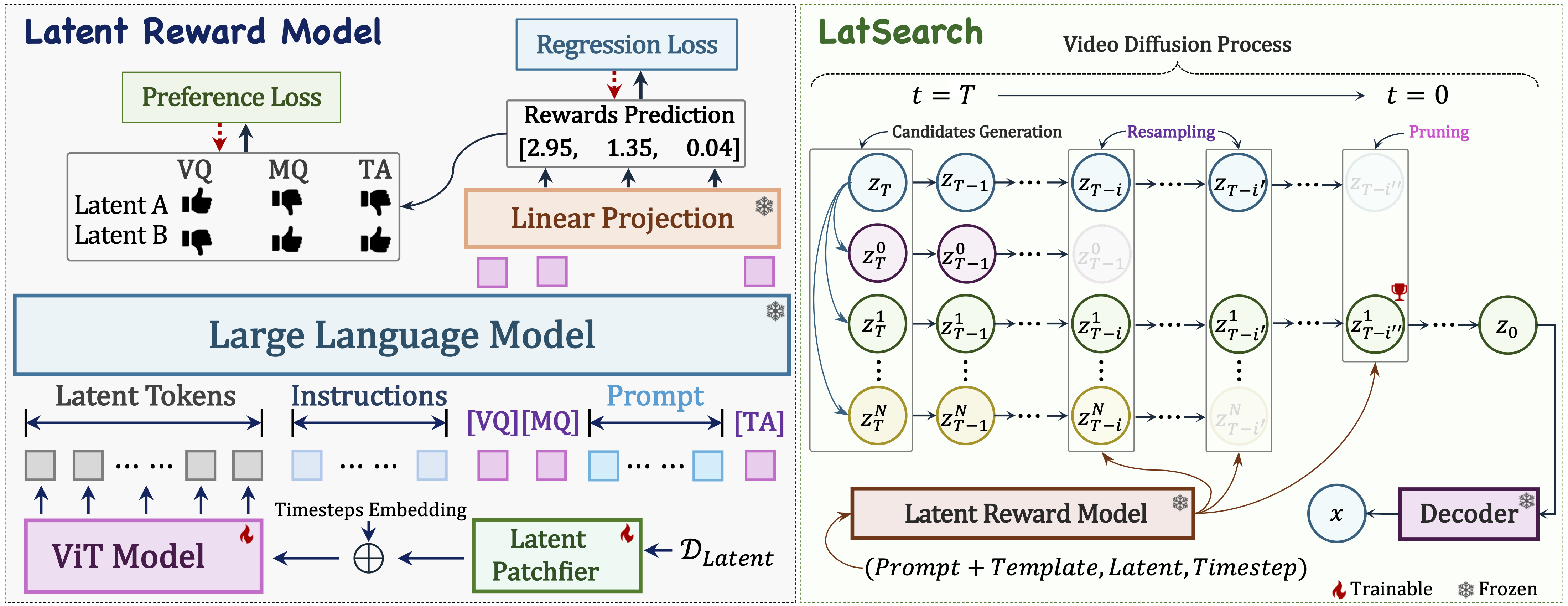
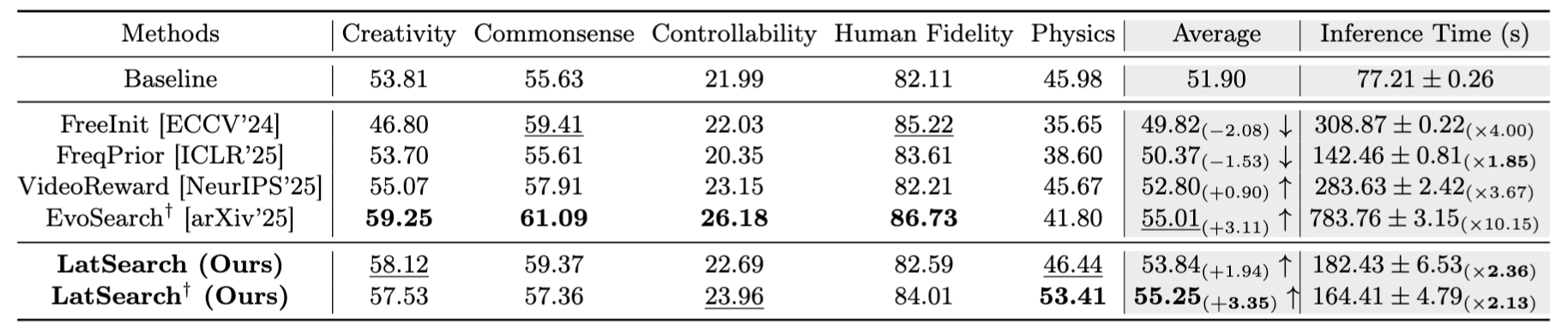
Figure 2: Comparison of inference-time scaling methods for video generation on VBench-2.0. The table includes both optimisation-based and search-based approaches. † indicates the use of DPM-Solver++. Bold numbers indicate the best results, while underlined numbers indicate the second-best. ↑ denotes performance degradation and ↓ denotes performance increase.