@inproceedings{zhao2025aim,
title={Aim-fair: Advancing algorithmic fairness via selectively fine-tuning biased models with contextual synthetic data},
author={Zhao, Zengqun and Liu, Ziquan and Cao, Yu and Gong, Shaogang and Patras, Ioannis},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={28748--28758},
year={2025}
}
AIM-Fair: Advancing Algorithmic Fairness via Selectively Fine-Tuning Biased Models with Contextual Synthetic Data
CVPR 2025
Motivations
Recent advancements in text-to-image generative models showcase impressive data fidelity, yet their potential for improving fairness through data expansion has not been fully explored by the fairness community. This raises the question: can AI-generated synthetic data play a crucial role in mitigating biases within machine learning models?
This work presents a comprehensive empirical investigation into whether fine-tuning on high-quality, balanced generative data from a contemporary text-to-image model can counteract model biases caused by training on imbalanced real data. We identify two key challenges in bias-correcting fine-tuning with synthetic data:
(1) A data-related challenge arising from linguistic ambiguity of the textual prompt and/or model misrepresentation, which results in low-quality and low-diversity generated data.
(2) A model learning challenge caused by both a domain shift (synthetic vs. real) and a bias shift (unbiased vs. biased) between the real and the synthetic data. Fine-tuning blindly on the synthetic will result in a model with decreased utility.
Method
A selective fine-tuning model consisting of three parts: (1) Contextual Synthetic Data Generation (CSDG) for generating diverse images using GPT-4 generated prompts, (2) Selective Mask Generation (SMG) for creating a selection mask that determines which parameters are updated during fine-tuning, and (3) Selective Fine-Tuning (SFT) to enhance model fairness obtained from synthetic data whilst simultaneously to preserve model utility yielded from real data in pre-training.
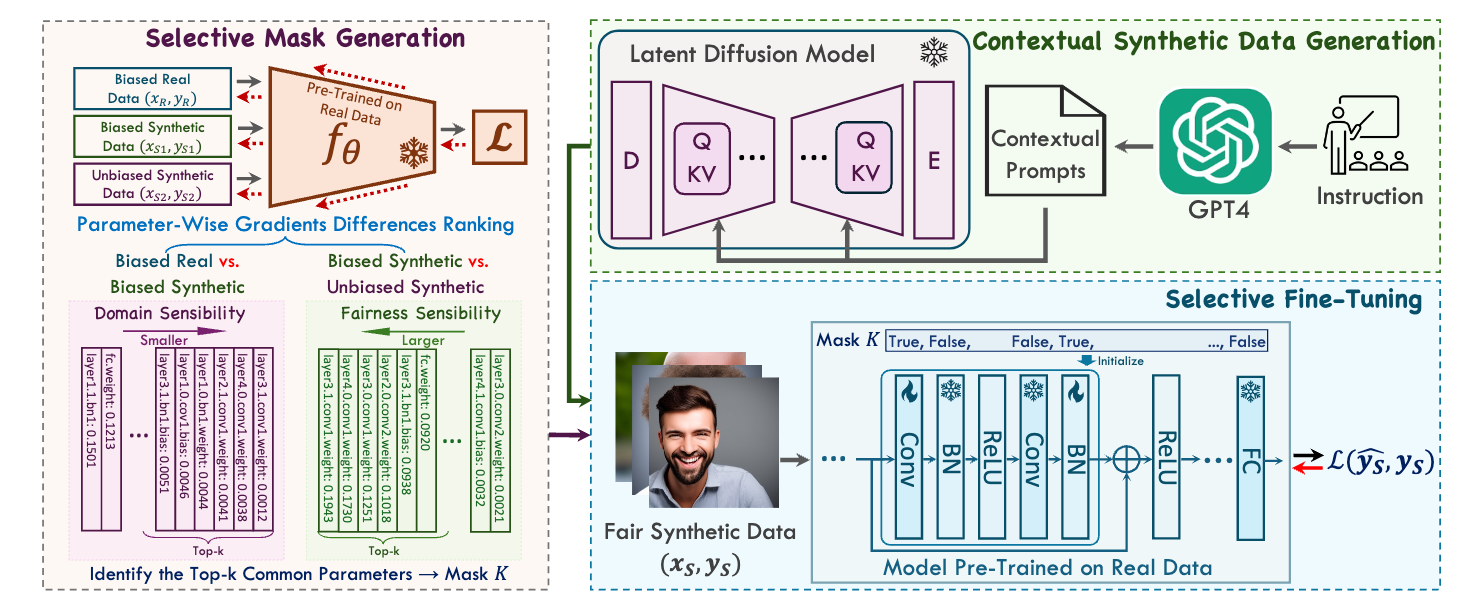
Results
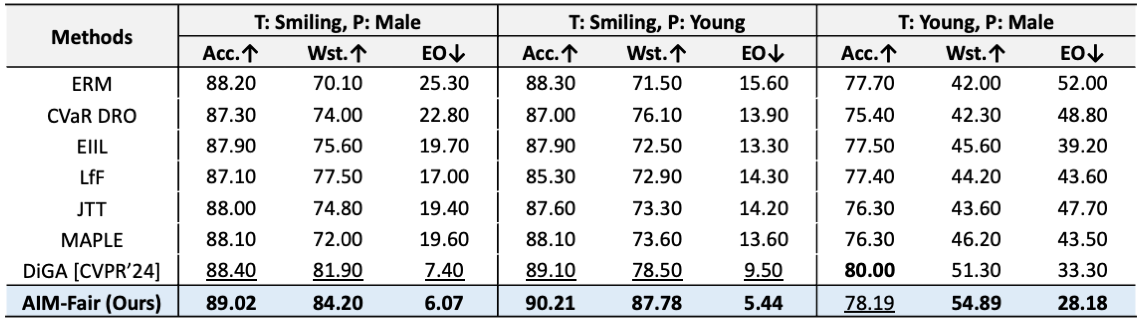
Comparisons to other methods on the CelebA dataset under settings of varied target and protected attributes.
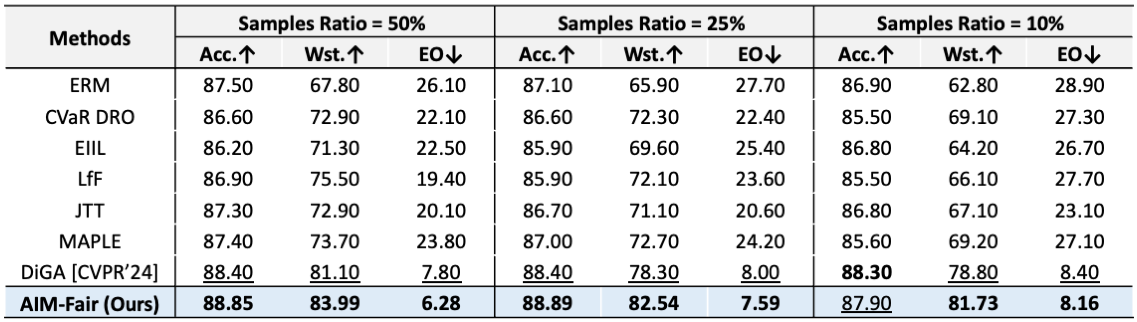
Comparisons to other methods on the CelebA dataset (T=Smiling, P=Male) under settings of training set sizes.
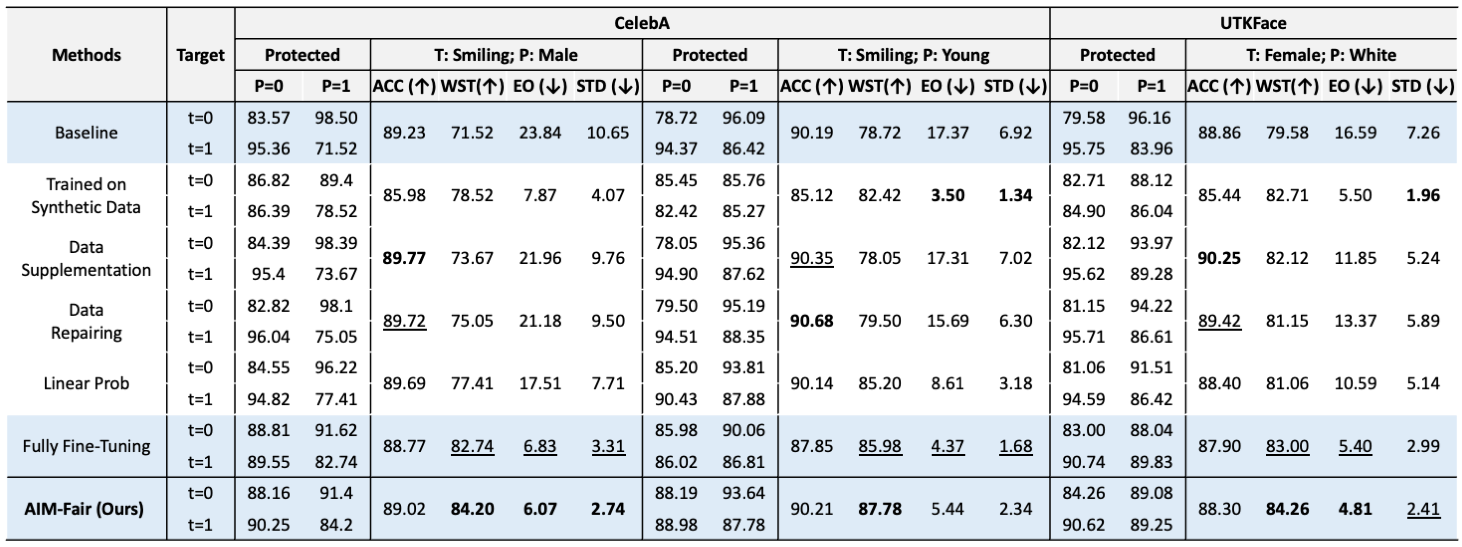
Comparisons of varied training strategies on CelebA and UTKFace datasets.
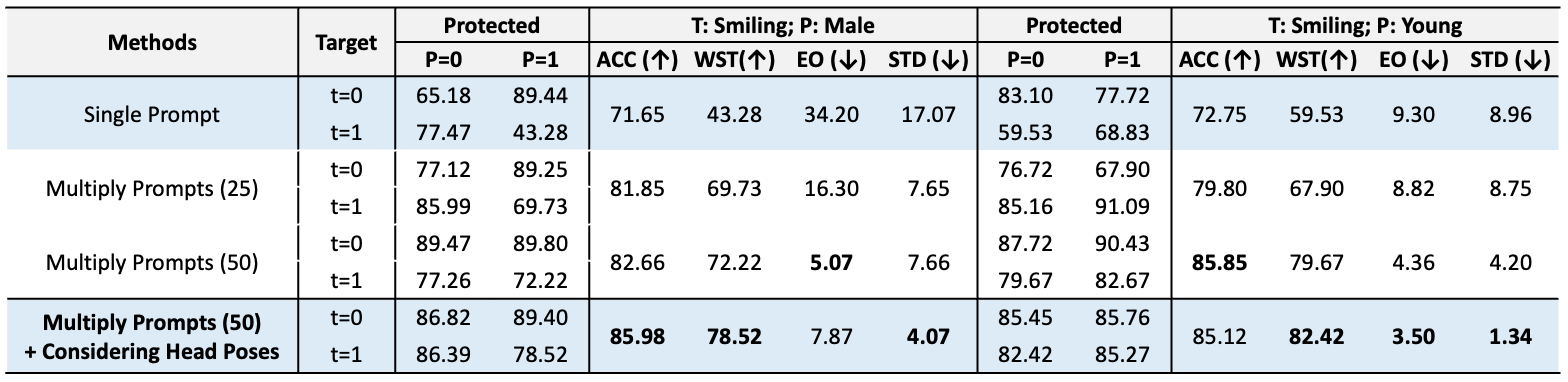
Results on CelebA dataset (T=Smiling, P=Male) under settings of different prompt types and numbers.
Visualizations
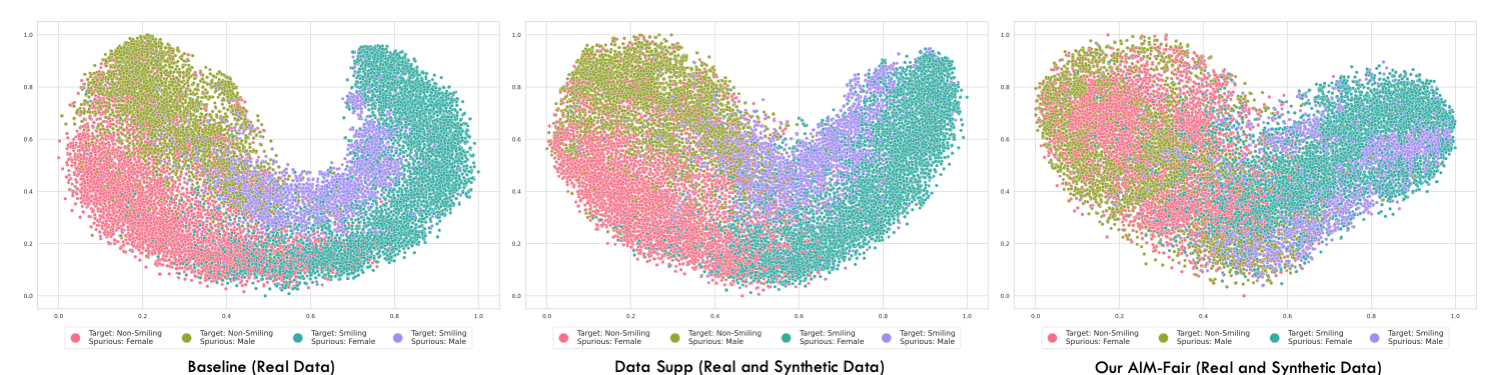
T-SNE visualizations for the learned representations on CelebA (T=Smiling, P=Male).

Generated contextual images for CelebA with target attribute Smiling and protected attribute Young.

Generated contextual images for UTKFace with target attribute Female and protected attribute White.